 Welcome
Welcome Source for Julia scripts, etc.
Source for Julia scripts, etc.
| ● | Ascii | Show Ascii character set (or: extended). |
| ● | Hexprint | Print hexadecimal dump of file (hilites bad characters: example). |
| ● | TzMulti | Generate Dada poems. |
| ● | BP | Record blood pressure readings. |
| ● | NUBP | More analysis of blood pressure readings. |
| ● | ZZ | Generate boilerplate for White House website user comments against President Biden's Ukraine war. |
| ● | del | Delete file(s) after taking a backup ("..\deleted\..."). |
| ● | Sc9 | String search all old Cloud9 html files. |
| ● | C9images | Find images used in new website from old. |
 | ||
| ● | w/DICT | Dictionary from image names to their [Wiki structure] directories (produced by w/WBCount). |
| ● | WBCTR | Count WB file updates. |
| ● | WBBKUPID | Current backup file serialization number. |
| ● | WBLOG-TS | Last backup timestamp (from WBupdate). |
| ● | V1 | List of all HTML Files in this website w/ their version numbers. |
| ● | V2 | List recently added (and changed) images. |
| ||
| ● | WBInclusions | Included data for other scripts (229). |
| ● | WB_Transforms | Shorthand WB transformations. |
| ● | WB | Process HTML "templates" (plus: backup file ("..\backups\...") and update version stamp). |
| ● | WBdiff | Check if HTML file changed after WB edit. |
| ● | WBafter | List most recently changed HTML and image files. |
| ● | WBupdate | Update timestamp of last upload of files to Dreamhost (produces WBLOG-TS). |
| ● | WBTree | Produce cross references of links in website, and V1 file. |
| ● | w/WBCount | Produce directory (w/DICT) of image files in website. |
| ● | WBSearch | String search utility for HTML files in this website. [ "%%1%" for "^", "%%2%" for ">" ] |
| ● | WBMap | Map depth of internal page links in website. |
| ● | WBM | Count WB Macro invocations. |
| ● | w/WBcompare | Verify that image files in Dreamhost are up to date. |
| ● | WBheads | Validate external links. |
| ● | WBY | List most recently added image files (produces V2 file). |
| ● | WBW | Automate updating HTML and image files in remote install of source code (processes V1 and V2 files). |
| ● | WBX | Do global text replacements on all HTML files in this website (incl. update version stamps). |
| ● | WBZ | Generate directory locations for image files. |
| ● | Quora | Generate TOC for a Quora log page. |
Σ 4,488(+703) loc. 189,967 chars. | ||
 |
    |
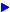
{kind=link}